大数据技术入门 ZooKeeper分布式协调服务与数据处理
在大数据技术的广阔领域中,分布式系统的协调与管理是核心挑战之一。Apache ZooKeeper作为一个开源的分布式协调服务框架,为解决这一问题提供了强大而可靠的解决方案。它尤其在大规模分布式数据处理服务中扮演着至关重要的角色。
一、ZooKeeper概述
ZooKeeper本质上是一个为分布式应用提供一致性服务的软件。它通过一个简单的分层命名空间(类似于文件系统)来存储数据,并允许分布式进程通过共享这个命名空间来实现相互协调。其设计目标是简化分布式应用开发的复杂性,提供诸如配置维护、命名服务、分布式同步和组服务等核心功能。
ZooKeeper的核心思想是提供一个简单、高性能、高可用且严格有序的协调服务。它通过一个由多个服务器(节点)组成的集群来保证高可用性,即使部分节点失效,整个服务依然能够继续运行。
二、核心概念入门
对于初学者,理解以下几个核心概念是掌握ZooKeeper的关键:
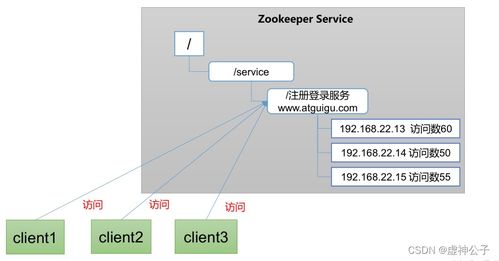
- 数据模型(ZNodes): ZooKeeper的数据存储在一个类似于文件系统的树形结构中,每个节点称为一个“ZNode”。ZNode既可以存储数据(字节数组),也可以拥有子节点。ZNode分为持久节点和临时节点,临时节点在客户端会话结束后会自动消失,这一特性常用于服务发现和存活检测。
- 会话(Session): 客户端通过与ZooKeeper集群中的一个服务器建立TCP连接来创建一个会话。会话具有超时时间,在会话期间,客户端可以发送请求并接收响应、监听事件。通过心跳机制维持会话活性。
- 监视(Watcher): 客户端可以在特定的ZNode上设置监视点(Watcher)。当该ZNode的状态发生变化(如数据被修改、子节点列表变更等)时,ZooKeeper服务器会向客户端发送一个一次性的事件通知。这是一种高效的、推送式的通知机制,避免了客户端轮询的开销。
- 一致性保证: ZooKeeper提供顺序一致性,即所有更新请求都按照其被发送的顺序执行。它通过Zab(ZooKeeper Atomic Broadcast)协议来保证集群中各服务器状态的一致性。
三、在数据处理服务中的应用
ZooKeeper在大数据生态系统的数据处理服务中应用极为广泛,是许多顶级项目(如Apache Kafka, Apache HBase, Apache Hadoop YARN, Apache Solr等)的核心依赖。其主要应用场景包括:
- 配置管理: 在分布式系统中,将配置信息集中存储在ZooKeeper中。所有服务节点可以监听配置ZNode,当配置更新时,ZooKeeper会通知所有监听者,实现配置的动态、统一更新,无需重启服务。这对于数据处理管道的参数调整至关重要。
- 命名服务与服务发现: ZooKeeper可以作为一个全局的命名服务。数据处理服务(如Spark作业、Flink任务)的实例在启动时,可以在ZooKeeper上创建一个临时ZNode来注册自己(例如,包含其主机名和端口)。客户端或其他服务可以通过查询ZooKeeper来发现当前可用的服务实例,实现负载均衡和故障转移。
- 分布式锁: 在并发数据处理场景下(如多个作业试图同时写入同一个HBase表),需要一种机制来保证互斥访问。利用ZooKeeper有序临时节点的特性,可以轻松实现公平的分布式锁,协调多个进程对共享资源的访问顺序。
- 领导者选举: 许多分布式数据处理框架(如Kafka的Controller、HDFS的NameNode HA)都需要一个主节点来协调工作。ZooKeeper提供了一种简单可靠的领导者选举机制。多个候选节点同时尝试创建同一个ZNode(例如
/election/master),最终只有一个能创建成功,该节点即成为领导者。其他节点则监听该ZNode,一旦领导者失效(会话结束,其临时节点被删除),剩下的节点将重新发起选举。
- 集群状态管理与心跳: 数据处理集群的各个节点可以通过在ZooKeeper上创建临时节点来标识自己的在线状态。集群管理器(如YARN ResourceManager)可以通过监控这些节点的存亡来感知集群的拓扑变化和节点故障,从而进行任务的重调度。
四、入门实践建议
- 环境搭建: 从官网下载ZooKeeper稳定版本。可以先在单机模式下运行(配置为单服务器模式)进行学习和测试,熟悉基本命令。随后尝试搭建一个由三台服务器组成的集群,体验其高可用特性。
- 命令行操作: 熟练使用ZooKeeper自带的命令行客户端
zkCli.sh,练习创建(持久/临时)节点、读取数据、设置监视、列出子节点等基本操作。 - 客户端编程: 使用Java、Python等语言的ZooKeeper客户端API编写简单的程序,实现上述的配置管理、服务注册发现或分布式锁的Demo,这是理解其工作原理的最佳途径。
- 结合大数据组件学习: 在学习Kafka、HBase等具体的大数据组件时,深入研究它们是如何依赖和使用ZooKeeper的,这能极大加深对ZooKeeper在真实场景中价值的理解。
###
ZooKeeper作为分布式系统的“基石”,通过提供一套简单而强大的原语,将复杂的分布式协同问题标准化。对于从事大数据和分布式数据处理服务的开发者而言,深入理解并掌握ZooKeeper,是构建稳定、可靠、可扩展的分布式应用的关键一步。从核心概念入手,结合实践操作,便能逐步揭开其神秘面纱,并有效地将其应用于解决实际的分布式协调难题之中。
如若转载,请注明出处:http://www.puhuoyi.com/product/1.html
更新时间:2026-05-04 15:38:40